Introducción
La renta per cápita en términos reales de nuestra economía lleva estancada más de 15 años, mientras que la PTF se mantiene a nivel de los años 80 (consecuentemente, los salarios reales prácticamente no crecen), además, no hemos conseguido recortar la distancia con Europa, es decir, no hemos convergido y nuestro bienestar económico lleva décadas estancado. Para profundizar en estos temas se pueden ver las dos conferencias siguientes:
Es entendible que el lector prefiera creerme y no verse dos horas de contenido audiovisual no demasiado estimulante pero sí muy pesimista, podría decir que no creo que la fe sea suficiente (al menos a la hora de hablar de crecimiento económico) y dar argumentos que justifiquen las afirmaciones previas, pero como con las 5 medidas que voy a proponer tendréis que hacer un salto de fe, mejor empezar ya, así arreglaremos España cuanto antes y evitaremos que suceda lo que dice Jesús en una de las conferencias:
Vamos a camino de las bodas de plata, de 25 años de carencia de crecimiento económico.
En este contexto, es necesario y urgente proponer soluciones, el carácter de las mismas puede ser muy diverso, pero aquí no estamos para pensar en que suena mejor o peor, estamos para arreglar las cosas, hay que ser técnicos y maximizar el bienestar social, por tanto, empezamos ya.
2. Contaminar mucho, NO al mercado de permisos de emisión de CO2.
Podemos ver que España es un cero a la izquierda cuando hablamos de contaminación a nivel mundial, ahora veremos los datos representados gráficamente y en un mapa de coropletas, pero ya hago yo un adelanto: emitimos el 0.6% de todas las toneladas métricas de CO2 que se emiten al año a nivel mundial, por lo que regular lo que va a pasar con los motores de combustión (especialmente con los diésel) y obligar a nuestras empresas a comprar permisos de emisión de CO2 cuyo precio no para de subir es sencillamente estúpido, todavía más cuando los que contaminan de verdad se pasan cualquier tipo de norma medioambiental por el Arco de Belén; o sea, seamos serios, vamos a hacer que las clases más vulnerables de nuestro país no puedan comprarse un coche nuevo porque van a costar 30.000 pavos (como poco), pero más del 60 % de la producción de electricidad en China se consigue quemando carbón1, ¿estamos locos?
Ahora bien, alguien podría decirme: “Oye Alejandro, pero es que si China e India emite el 35% del CO2 a escala mundial es, en parte, porque nosotros les compramos, y claro, achacarles toda esa contaminación a ellos y a nosotros solo un 0.6% no es justo, los datos subestiman nuestra contaminación y sobreestiman la suya”. Vale, ¿y? Me la pela. Aquí buscamos programar, arreglar la economía española no es más que una fachada, no vamos a ponernos a decir cosas serias.
Siguiendo con el análisis, evidentemente la contaminación que permitiríamos sería aquella cuyas externalidades negativas son a nivel global, nadie habla de cargarse el Mar Menor o de ponernos a destruir bosques a mansalva. Al final del día uno tiene que ser racional y pensar que la capa de ozono va a acabar pareciendo un queso de todas formas, da igual que hagamos o no hagamos nada (sí, no vamos a usar el argumento de que no tenemos que contaminar porque si nosotros no respetamos las leyes medioambientales habrá más gente que no lo haga, nuestra influencia en las decisiones del resto de países es, aproximadamente, -33). El único problema serio de no respetar las leyes medioambientales es que estamos en Europa y eso podría traernos muchos problemas y sanciones, pero no pasa nada, la solución para ese problemilla viene incluida en la cuarta medida.
En el siguiente gráfico podemos ver el total mundial de emisiones de CO2 en el año 2022, los datos los he sacado de Our World in Data, la verdad es que esta web me gusta mucho, si tuviese que hacer un ranking de webs que más frecuento (quitando las que ya sabemos que no puedo decir aquí 😉🤫) esta sería la primera sin ninguna duda. Podemos ver las aportaciones de diferentes países a esta lista, he puesto a varios de los que más emiten y a alguno de nuestro entorno. Podemos ver que nuestra influencia es, literalmente, insignificante:
Código
library(ggplot2)
library(gganimate)
library(hrbrthemes)
library(highcharter)
library(sf)
library(rnaturalearth)
library(rnaturalearthdata)
library(tmap)
options(scipen = 999)
polucion <- "https://github.com/aluse33/datos_trabajo/raw/main/pollution_data.csv"
download.file(url = polucion, destfile = "./datos/pollution_data.csv")
polucion <- rio::import("./datos/pollution_data.csv")
paises_que_molan <- c("World", "Spain", "United States", "India", "China", "European Union (27)", "Germany", "France")
polucion_paises <- polucion %>%
filter(Entity %in% paises_que_molan) %>%
filter(Year >= 1900) %>%
select(-Code)
spain <- polucion_paises %>% filter(Entity == "Spain")
USA <- polucion_paises %>% filter(Entity == "United States")
india <- polucion_paises %>% filter(Entity == "India")
EU <- polucion_paises %>% filter(Entity == "European Union (27)")
germany <- polucion_paises %>% filter(Entity == "Germany")
france <- polucion_paises %>% filter(Entity == "France")
world_pol <- polucion_paises %>% filter(Entity == "World")
china <- polucion_paises %>% filter(Entity == "China")
plot_pol <- highchart() %>%
hc_chart(type = "line") %>%
hc_add_series(spain, "line", hcaes(Year, `Annual CO₂ emissions`), name = "España") %>%
hc_add_series(USA, "line", hcaes(Year, `Annual CO₂ emissions`), name = "USA") %>%
hc_add_series(india, "line", hcaes(Year, `Annual CO₂ emissions`), name = "India") %>%
hc_add_series(EU, "line", hcaes(Year, `Annual CO₂ emissions`), name = "EU(27)") %>%
hc_add_series(germany, "line", hcaes(Year, `Annual CO₂ emissions`), name = "Alemania") %>%
hc_add_series(france, "line", hcaes(Year, `Annual CO₂ emissions`), name = "Francia") %>%
hc_add_series(china, "line", hcaes(Year, `Annual CO₂ emissions`), name = "China") %>%
hc_add_series(world_pol, "line", hcaes(Year, `Annual CO₂ emissions`), name = "Total mundial") %>% hc_title(text = "Emisiones de dióxido de carbono (CO₂) en el mundo, medidas en toneladas métricas al año.",
style = list(fontWeight = "Semi Bold", color = "black")) %>%
hc_subtitle(text = "Datos extraídos de Our World in Data.",
style = list(fontWeight = "Semi Bold",
color = "black"))
#- plot_polSi queremos verlo en un mapa resulta todavía más evidente, cuanto más oscuro más culpable (no penséis mal), y como podemos ver, son los que pensábamos:
Código
data(World)
world <- World
polucion <- polucion %>%
filter(Year == 2022) %>%
mutate(Entity = as.character(Entity)) %>%
filter(Entity != "World") %>%
rename(`Emisiones anuales de CO2` = `Annual CO₂ emissions`)
polucion_mapa <- left_join(polucion, World, by = c("Code" = "iso_a3"))
mapa_molon <- polucion_mapa %>%
ggplot() +
geom_sf(aes(fill = `Emisiones anuales de CO2`, geometry = geometry)) +
scale_fill_viridis_c(option = "inferno", trans = "sqrt", direction = -1) +
theme_void() +
labs(title = "Emisiones de dióxido de carbono (CO2) en el mundo." ) +
theme(plot.title = element_text(face = "bold")) +
labs(subtitle = "Año 2022. Datos de Our World in Data.") +
theme(panel.background = element_rect(fill = "azure"),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank()) +
guides(fill = FALSE)
#- mapa_molon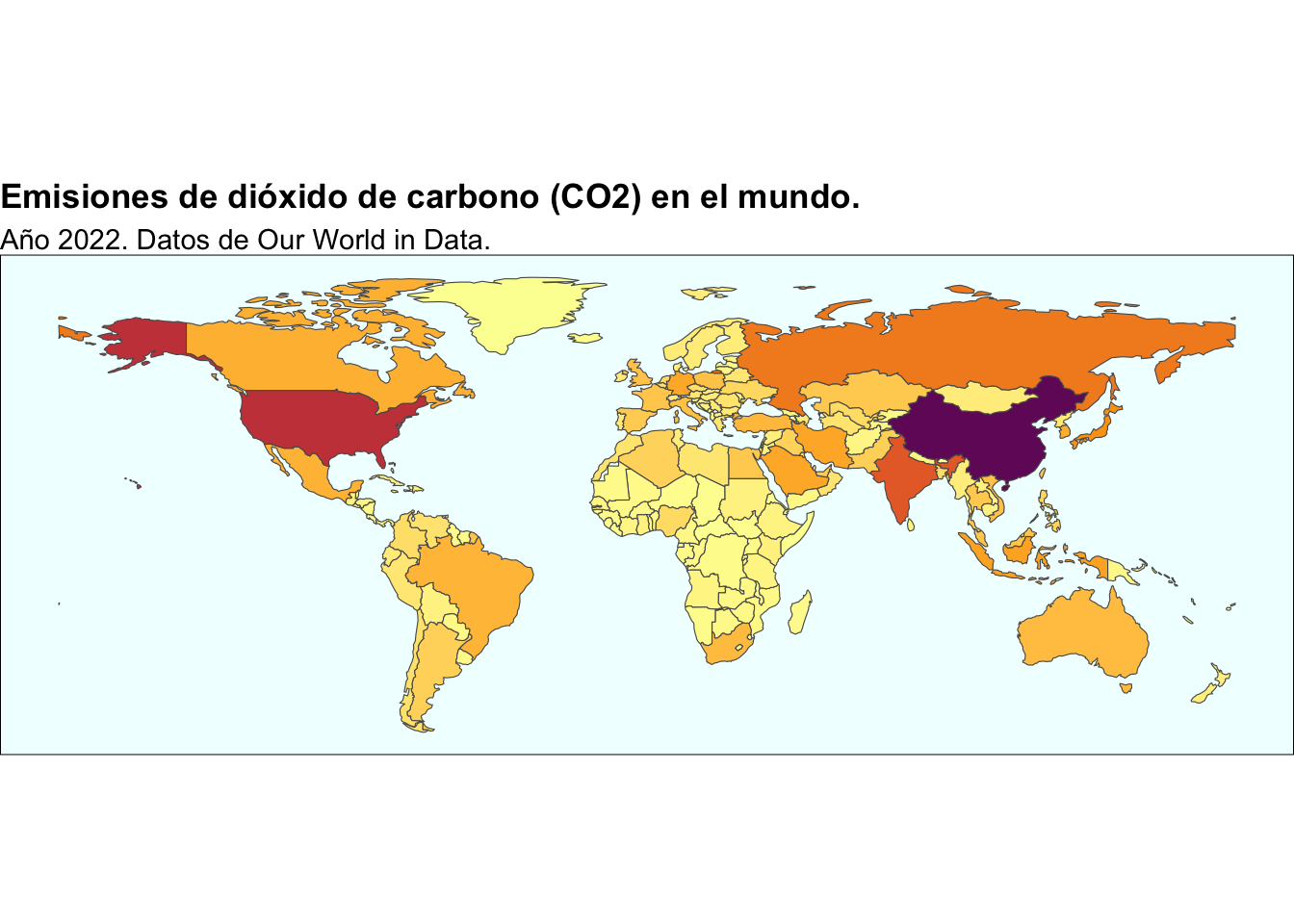
Visto lo visto, para potenciar nuestra economía es requisito sine qua non empezar a tomarnos en serio las cosas y olvidarnos de las idas de olla que se les ocurran a los políticos de Europa.
3. Maravedíes respaldados con uranio.
Vale, este punto quizá sea un pelín más técnico, pero no os preocupéis, se va a entender bien. Si recordáis la segunda medida, dije que contaminar mucho nos iba a traer problemas con Europa, bueno, pues por eso no pasa nada, porque la cuarta medida tiene dos partes, la primera parte es muy fácil de entender: sabotear a los países frugales lo máximo posible, es decir, hacer que nos rescaten y nos inyecten crédito a mansalva, crédito que, evidentemente, no les vamos a devolver. Aunque esto sea una putada para ellos, a nosotros nos tiene que dar igual, todo forma parte de el plan. La consecuencia directa es que nos echarían de la UE al instante, por lo que podríamos, todavía más, potenciar la segunda medida, ya que desaparece el yugo invisible que representa para nosotros la Comisión Europea. Que nos echen no significa que no podamos usar el euro, de hecho, Andorra mismamente, no forma parte de la UE y usa el euro, aunque resulta obvio que quizá no les parece bien que lo usemos. Bueno, en este contexto hemos de pensar que el euro vale, en la actualidad, prácticamente la mitad de lo que valía cuando nació (por lo que abandonarlo tampoco nos supondría un problema demasiado importante), esto es algo que se puede ver de manera muy chula en el siguiente gráfico (que he podido elaborar con este repo de github):
Código
library(jpeg)
library(grid)
library(ggplot2)
library(ggthemes)
#- cargamos los datos del ecb
URL <- "https://sdw-wsrest.ecb.europa.eu/service/data/ICP/M.ES.N.000000.4.INX?format=csvdata"
df <- read.csv(URL)[c("TIME_PERIOD", "OBS_VALUE")]
df$TIME_PERIOD <- seq.Date(as.Date("1996-02-01"), by="month", length.out = nrow(df)) - 1
df$OBS_VALUE <- as.numeric(df$OBS_VALUE)
df <- df[df$TIME_PERIOD >= as.Date("1999-12-31"),]
df$PPP <- df$OBS_VALUE[1]/df$OBS_VALUE
#- imagen billete
bill <- readJPEG("./imagenes/20_euros.jpg")
bill <- rasterGrob(bill, width=unit(1,"npc"), height=unit(1,"npc"), interpolate=TRUE)
#- gráfico
graph <- ggplot(df, aes(x = TIME_PERIOD, y = PPP)) +
#- dibujamos el billete
annotation_custom(bill, xmin = -Inf, xmax = Inf, ymin = 0, ymax = Inf) +
#- la parte blanca para delimitar
geom_ribbon(aes(ymin = PPP, ymax = Inf), fill = "white") +
geom_line(size=1, colour="#000000") +
geom_hline(yintercept=tail(df$PPP, 1), linetype="dashed") +
#- la escala
scale_x_date(date_breaks="3 year",date_labels = "%Y", expand=c(0,0)) +
scale_y_continuous(expand = c(0,0), labels = scales::percent, limits = c(0,1), breaks = seq(0, 1, 0.1)) +
#- labels
labs(
title = "Poder Adquisitivo del €uro en España",
subtitle = "Desde 2000 hasta 2023, siendo 1 de enero de 2000 = 100%",
x="",
y="",
caption="Elaboración con el repo de @jaldeko. Fuente datos: ECB Statistical Data Warehouse") +
# Add a theme and other aesthetics modifications
theme_minimal() +
theme(plot.caption = element_text(face="italic"),
plot.title = element_text(face="bold", hjust=0.5, size=rel(1.5)),
plot.subtitle = element_text(face="italic", hjust=0.5),
axis.text.x = element_text(colour = "black", hjust=-0.5, face="bold"),
axis.text.y = element_text(colour = "black", face="bold"),
plot.margin = unit(c(0.5,0.5,0.5,0.5), "cm"),
panel.grid.major.x = element_blank(),
panel.grid.minor = element_blank(),
axis.line = element_line(colour="black"),
axis.ticks = element_line(colour="black"),
legend.key.height = unit(0.75, 'cm'),
legend.text = element_text(colour = "black", face="italic", size=rel(0.75)))
#- graph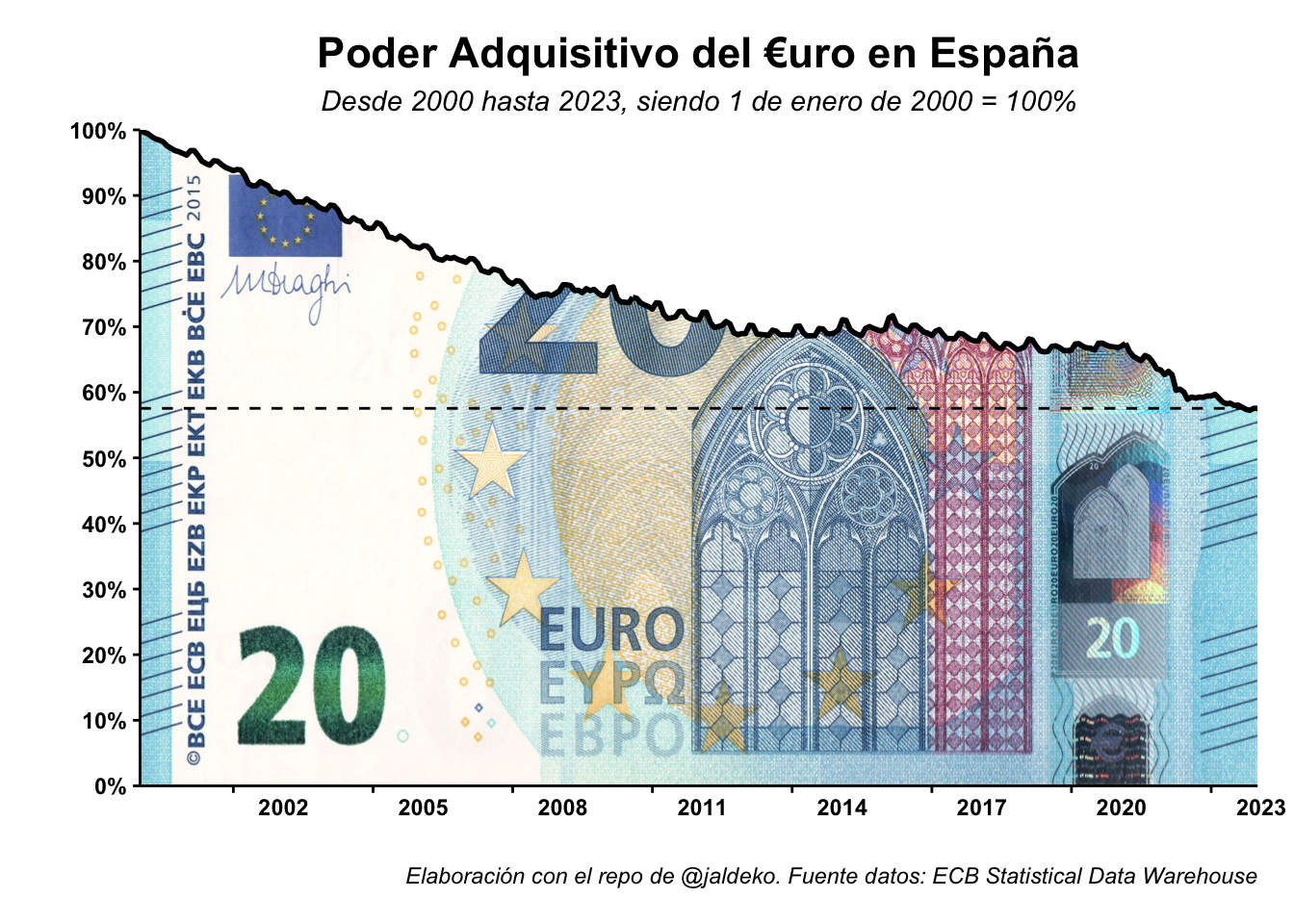
Es importante actuar rápido, ya sabemos que dejar la autoridad monetaria en manos de nuestros políticos no es una opción, salvo que queramos pasar a ser Argentina en un día medio (aproximadamente). Otra opción sería que, si el banco central fuese independiente (de verdad), hubiese tipos muy técnicos tomando las decisiones, bien, eso puede traernos problemas en el largo plazo en función del grado de independencia que mantenga el BC, por lo que lo mejor será olvidarnos de esta opción.
La solución es mucho más sencilla, traer de vuelta los maravedíes y respaldar su valor con reservas de uranio, algo así como el Patrón Oro, pero un poco más moderno y con una curva de oferta mucho más “ideal” para nuestra moneda. La idea básica es la siguiente (permítanme hablar un poco de física):
- Un átomo de uranio-238 (el isótopo más común del uranio, vaya) sigue un proceso de desintegración estocástico.
- La probabilidad de desintegración es directamente proporcional al número de átomos presentes en ese momento.
- Esta relación la podemos expresar con la ecuación diferencial de la ley de desintegración radiactiva (si algún lector ha ido a Matemáticas conmigo este curso debería saber esto):
\[\frac{dN}{dt} = -\lambda N\] Siendo \(\frac{dN}{dt}\) la tasa de variación del número de átomos con respecto al tiempo, \(N\) la cantidad de átomos en un momento concreto y \(-\lambda\) la constante de desintegración del uranio-238.
Bueno, se resuelve de manera bastante sencilla, pensemos que es una EDO (ecuación diferencial ordinaria) lineal de primer orden, primero reordenamos:
\[\frac{1}{N}\frac{dN}{dt} = -\lambda\] Habiendo reordenado los factores podemos integrar y obtener la solución general de nuestra EDO: \[\int \frac{1}{N} \, dN = -\lambda \int \, dt\] De modo que tenemos:
\[\ln(N) = -t\lambda + C\] Finalmente, aplicando exponenciales y reordenando tenemos que la solución general es: \[N(t) = N_0 \cdot e^{-\lambda t}\]
Es decir, la cantidad de átomos en \(N(t)\) es igual a la cantidad de átomos en el momento \(0\) por \(e\) elevado a \(-\lambda\) por el número de periodos que estemos considerando (\(t\)).
Una vez tenemos en cuenta esta ley, podemos dar unos valores arbitrarios a las variables y a las constantes y representar gráficamente la función exponencial, sabiendo, eso sí, que como la probabilidad de desintegración del uranio es del 100% (esto quiere decir que sí o sí la curva sería como se representa en el gráfico), la oferta de maravedíes seguiría exactamente el mismo patrón (pero en negativo) que la desintegración natural de nuestras reservas de uranio, patrón que podemos considerar ideal. Podemos considerar esta curva ideal para la oferta monetaria de España después de aplicar las medidas mencionadas por estos dos motivos:
Boom económico (buenas medidas aplicadas y por aplicar) que impulsa mucho la demanda de dinero, por lo que, si al principio el aumento de M es exponencial, no pasa nada, porque la demanda de M también es creciente.
Estancamiento después del paso de unos cuantos periodos (curva casi plana), algo favorable ya que, como sabemos, los países ricos tienden a estancarse económicamente; por lo que nuestro estancamiento coincidiría con el momento en el que las reservas de uranio no dan para más y, consecuentemente, la oferta monetaria tampoco crecería (como somos economistas vamos a suponer que todo lo demás permanece constante y los bancos no crean dinero por medio del préstamo de los depósitos).
Aquí podemos ver la explicación gráficamente:
Código
#- Maravedí de uranio
ley_desintegracion <- function(t, lambda) {
exp(-lambda * t)
}
lambda_uranio238 <- 0.0005
data_uranio238 <- data.frame(t = seq(0, 10000, by = 1),
N = ley_desintegracion(seq(0, 10000, by = 1), lambda_uranio238))
#- ahora, solamente calculamos la contraparte negativa, para ver el movimiento de M
data_uranio238_neg <- data_uranio238 %>%
mutate(neg = -N) %>%
select(t, neg)
plot_uranio238 <- ggplot(data_uranio238, aes(x = t, y = N)) +
geom_line(color = "blue", size = 1.2) +
geom_line(data = data_uranio238_neg, aes(x = t, y = neg), color = "red", size = 1.2) +
labs(title = "Proceso de desintegración de un átomo de uranio-238 y patrón que seguiría la oferta de maravadíes",
x = "Periodos t",
y = "Fracción de átomos restantes y su valor negativo") +
labs(subtitle = "(Desintegración en azul y patrón automático de la oferta monetaria en rojo)") +
geom_hline(yintercept = 0, linetype = "dashed", color = "green", size = 1) +
theme_hc() +
theme(plot.title = element_text(hjust = 0.4, size = 9, face = "bold"),
axis.text = element_text(size = 10),
axis.title = element_text(size = 10),
legend.position = "none") +
theme(plot.subtitle = element_text(hjust = 0.5, size = 9, face = "italic"),
axis.text = element_text(size = 8),
axis.title = element_text(size = 8),
legend.position = "none")
#- plot_uranio238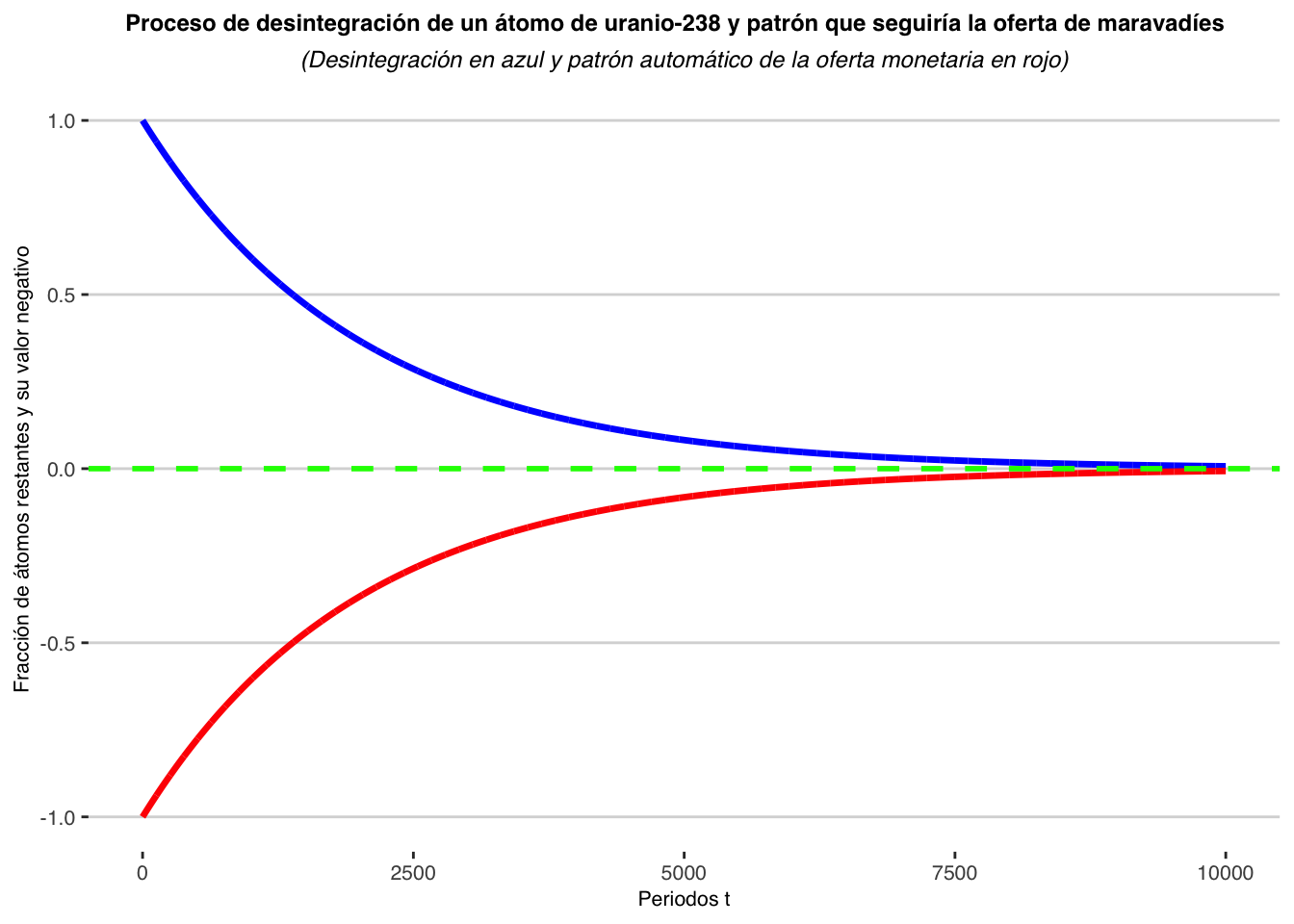
Una vez hecho esto, tendríamos un sistema monetario estable y acorde a los requerimientos de nuestra economía, sin embargo, es importante considerar las dos últimas medidas, ya que nuestro objetivo es que todo salga bien (i.e. haya convergencia) y no puedde quedar ningún cabo suelto.
4. Sufragio joven.
Bien es sabido por los lectores potenciales, después de haber visto los trabajos expuestos en clase por mis compañeros (los disponibles en la web, que la situación en la que se encuentran los jóvenes en la actualidad es especialmente delicada. Los resultados no son para nada positivos en términos de empleo, salarios, o patrimonio inmobiliario, entre otras variables a considerar.
En este contexto, uno debe tener en cuenta que en el juego de la democracia una mayoría impone sus intereses, más o menos homogéneos, sobre otra minoría, que no puede más que resignarse a aceptar los resultados (ya que la desobediencia civil no es una opción 🥱). Si hablamos de redistribución de la riqueza, al menos en el caso de España, esto resulta todavía más evidente, los jubilados, sin saber muy bien cómo, votan organizadamente con un interés común: que nadie les toque la pensión. De modo que, si uno mira los programas de los distintos partidos, absolutamente nadie habla de recortar esta partida (recordemos que es la mayoritaria) de los presupuestos. O sea, tenemos a políticos muy poco espabilados quejándose de que el Ministerio de Igualdad cuesta 500 millones de euros al año y hablando de qué se haría si nos ahorramos ese dinero; bueno, es que las pensiones cuestan esos 500 millones AL DÍA2. Nadie habla de bajarle o dejar de revalorizarle la pensión a aquel que cobra la mínima, pero seamos serios, que el tío abuelo de un amigo mío cobre 2.500 euros de pensión al mes no es lógico, vale que tiene que amueblar su cuarto piso y hay que ser comprensivos, pero no me vale; o sea, con dos sueldos de la Citroën pagó el piso, y no contento con eso, pudo comprar vivienda barata de la Sareb en pleno centro de Madrid para luego venderla a precio de mercado (spoiler: era de protección oficial).
De hecho, si estudiamos los datos de renta anual neta media por persona (datos del INE para el aó 2022), veremos que los jubilados son el grupo de edad más privilegiado (recordemos que no trabajan y el resto de los ciudadanos les pagan las pensiones) y aquí, un servidor ha querido ser bueno, ya que podría haber mostrado los mismos datos pero con los alquileres imputados (algo muy normal a la hora de medir este tipo de datos); si hubiésemos hecho esto, evidentemente las estadísticas serían mucho más dramáticas: los jóvenes prácticamente no tienen vivienda (por lo que el valor sería el mismo), pero la práctica totalidad de los jubilados sí que tiene, por lo que su renta neta (con alquileres imputados) habría sido notablemente mayor:
Código
library(tidyverse)
library(dplyr)
library(ggplot2)
library(ggthemes)
library(plotly)
renta <- "https://github.com/aluse33/datos_trabajo/raw/main/9942.xlsx"
download.file(url = renta, destfile = "./datos/9942.xlsx")
renta <- rio::import("./datos/9942.xlsx")
renta <- renta %>%
slice(9:13) %>%
select("Resultados nacionales":"...16") %>%
slice(c(5, 1:(4), (6: n())))
renta <- renta %>% slice(1:5) %>%
rename(
`Edad` = `Resultados nacionales`,
`2022` = ...2,
`2021` = ...3,
`2020` = ...4,
`2019` = ...5,
`2018` = ...6,
`2017` = ...7,
`2016` = ...8,
`2015` = ...9,
`2014` = ...10,
`2013` = ...11,
`2012` = ...12,
`2011` = ...13,
`2010` = ...14,
`2009` = ...15,
`2008` = ...16
) %>%
pivot_longer(
cols = c(`2022`, `2021`, `2020`, `2019`, `2018`, `2017`, `2016`, `2015`, `2014`, `2013`, `2012`, `2011`, `2010`, `2009`, `2008`),
names_to = "Año",
values_to = "Renta neta media"
)
renta22 <- renta %>% filter(Año == 2022) %>% select(Edad, `Renta neta media`)
#- cambiamos el formato de los datos porque si no nos joden para hacer los gráficos
renta$`Renta neta media` <- as.numeric(renta$`Renta neta media`)
renta$Año <- factor(renta$Año)
renta22$Edad <- factor(renta22$Edad, levels = c("Menos de 18 años", "De 16 a 29 años", "De 30 a 44 años", "De 45 a 64 años", "65 y más años"))
renta22$`Renta neta media` <- as.numeric(renta22$`Renta neta media`)
#- gráfico barras 2022
barras_renta22 <- renta22 %>%
ggplot(aes(x = Edad, y = `Renta neta media`, fill = Edad)) +
geom_bar(stat = "identity") +
labs(title = "Renta anual neta media en España por grupos de edad.",
subtitle = "Año 2022, medida en €.",
x = "Grupo de Edad",
y = "Renta neta media") +
theme_clean() +
theme(legend.position = "none")
#- barras_renta22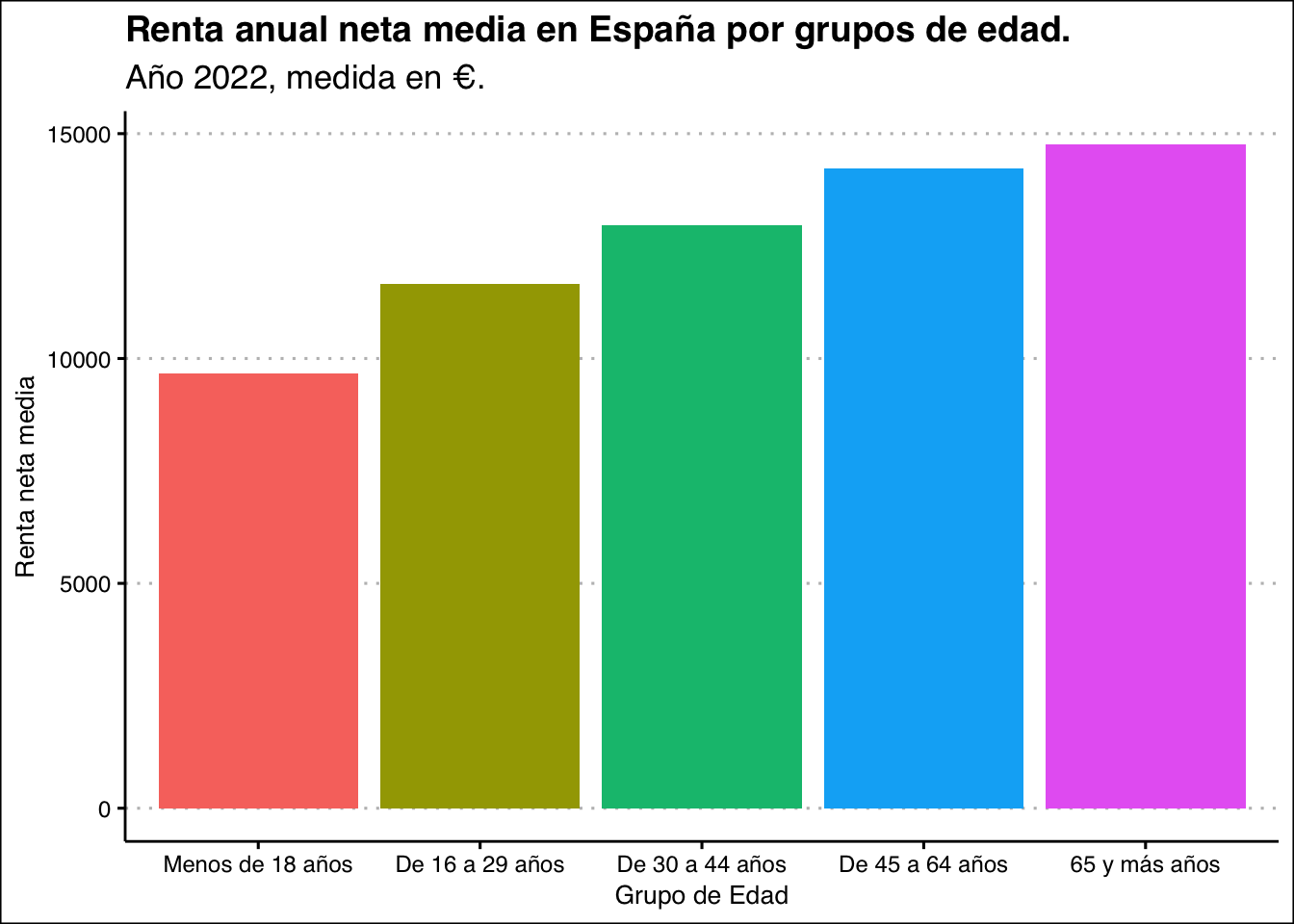
Lo mismo sucede si analizamos la evolución de esta variable en la última década; también podemos comprobar que los jóvenes fueron el grupo de edad más perjudicado por el boom inmobiliario del año 2008:
Código
grafico_renta <- renta %>%
ggplot(aes(x = Año, y = `Renta neta media`, group = Edad, color = Edad)) +
geom_line() +
labs(title = "Evolución de la renta neta anual media en € por grupo de edad en España, año 2008 a 2022.",
x = "Año",
y = "Renta neta media") +
theme_clean() +
theme(legend.position = "top")
#- ggplotly(grafico_renta)Conociendo esto y lo visto en las exposiciones de clase, queda evidenciado que no nos queda nada por hacer, terminar durante una década con el sufragio de los pensionistas es nuestra única opción, cierto es que vivieron una Guerra Civil y una dictadura, pero si conseguimos cambiar el relato para hacer creer a la sociedad que todo eso pasó en Call of Duty puede que aún nos quede algo de esperanza. Al fin y al cabo, de nada nos sirve mejorar la productividad de nuestra economía, crecer, y tener un sistema monetario que nos facilite estos objetivos si el 40% de los presupuestos (con cargo al endeudamiento) se van a cubrir interesesde un grupo en el que hay bastantes privilegiados.
5. Neo-España y nuevas “estadísticas”.
Finalmente, esta es una medida que no me gustaría que se tuviese que aplicar, pero es cierto que, por muy buenas que sean las ideas ya propuestas, siempre existe un margen de error que hay que considerar, de manera que tener un plan B es necesario, sobre todo por si llegasemos a una situación en la que, ya habiendo aplicado lo mencionado, todavía no hemos convergido con las economías más avanzadas.
Este plan B es un poco macabro, consiste en manipular las estadísticas de renta per cápita, pero esto lo podríamos conseguir way easier, la idea básica es, conociendo la renta anual neta media por hogar en el año 2022 (obtenida del INE), expulsar de España a aquellas comunidades que nos bajan la media, de modo que, de manera automática, la media podría subir y, aunque el nivel de bienestar de los que nos quedamos sea el mismo (y de los que se van, claro), podríamos aparecer en puestos superiores en los índices que comaparan el nivel de bienestar económico de los países.
Esta es la distribución de la renta anual neta de los hogares por comunidades autónomas:
Código
library(rio)
library(tidyverse)
library(dplyr)
library(tidyr)
library(tmap)
library(ggplot2)
library(plotly)
renta_com <- "https://github.com/aluse33/datos_trabajo/raw/main/9949.xlsx"
download.file(url = renta_com, destfile = "./datos/9949.xlsx")
renta_com <- rio::import("./datos/9949.xlsx")
renta_com <- renta_com %>%
slice(8:27) %>%
rename(CCAA = `Resultados por comunidades autónomas`, `Renta anual neta media por hogar 2022` = ...2)
renta_com$`Renta anual neta media por hogar 2022` <- as.numeric(renta_com$`Renta anual neta media por hogar 2022`)
#- cargo los datos geográficos (en verdad esto es la hostia, que Pedro haya hecho un paquete así me parece una locura, pero bueno, vamo a seguir, que me quedan dos exámenes)
geo_df <- pjpv.curso.R.2022::LAU2_prov_2020_canarias
geo_ccaa <- geo_df %>%
select(ine_ccaa, ine_ccaa.n, geometry)
renta_com <- renta_com %>%
separate(CCAA, sep = " ",
into = c("ine_ccaa", "ine_ccaa.n"), extra = "merge") %>%
slice(2:20)
renta_com_geo <- left_join(geo_ccaa, renta_com, by = c("ine_ccaa" = "ine_ccaa"))
mapa_renta_com <- renta_com_geo %>%
ggplot() +
geom_sf(aes(fill = `Renta anual neta media por hogar 2022`, geometry = geometry), color = "black", size = .1) +
coord_sf(xlim = c(-12, 5), ylim = c(35,45)) +
scale_fill_viridis_c(option = "plasma", trans = "sqrt", direction = -1) +
labs(title = "Renta por hogar anual neta media por hogar en España." ) +
theme(plot.title = element_text(face = "bold")) +
labs(subtitle = "Año 2022.") +
labs(fill = "Renta en miles de €:") +
labs(caption = "Datos obtenidos en la web del INE.") +
theme_void() +
theme(panel.background = element_rect(fill = "azure"),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank())
#- mapa_renta_com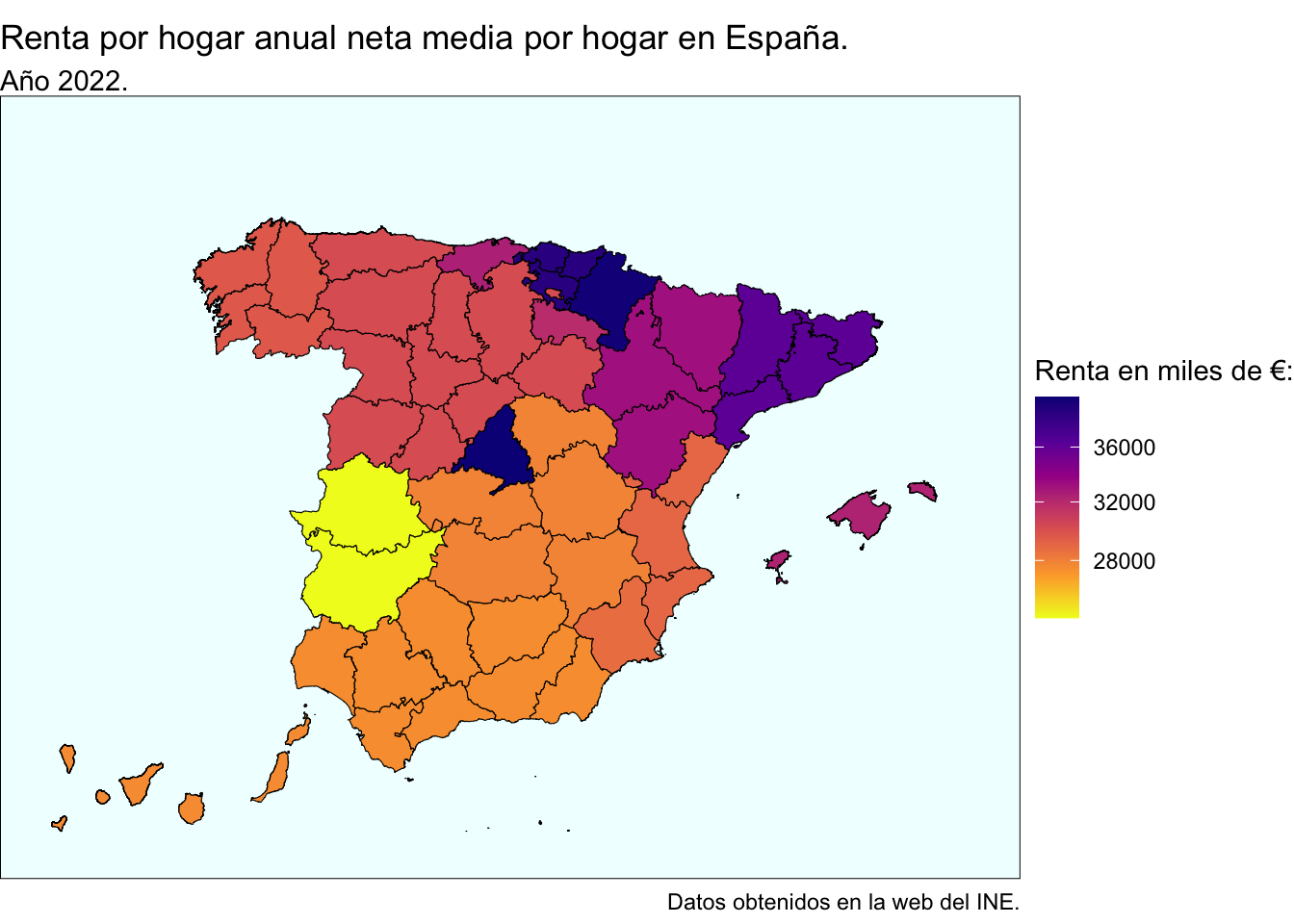
Como vemos, algunas comunidades no han hecho los deberes y sus resultados son bastante mejorables. Realmente no pasa nada, geográficamente seguirán al lado y desde Neo-España les podremos ayudar: los convenios entre países cercanos están a la orden del día en materia sanitaria, comercial, laboral, etc. Las regiones seleccionadas en función de los valores de su renta neta media por hogar son Extremadura, Andalucía y Canarias. Es cierto que siguiendo este criterio Castilla-La Mancha debería estar fuera también, pero hay un motivo fundamental por el que se queda dentro: un servidor es conquense y se mueve mucho entre Cuenca y Valencia, por lo que habría ciertas complicaciones técnicas todos los meses y determinados gastos derivados que no estoy dispuesto a asumir, de modo que Castilla se queda en Neo-España.
El nuevo mapa quedaría tal que así:
Código
#- vamos a secesionar un poco
pobres <- c("Andalucía", "Extremadura", "Canarias")
renta_sin_pobres <- renta_com_geo %>%
select(-ine_ccaa.n.y) %>%
filter(!(ine_ccaa.n.x %in% pobres))
mapa_renta_sin <- renta_sin_pobres %>%
ggplot() +
geom_sf(aes(fill = `Renta anual neta media por hogar 2022`, geometry = geometry), color = "black", size = .1) +
coord_sf(xlim = c(-12, 5), ylim = c(35,45)) +
scale_fill_viridis_c(option = "inferno", trans = "sqrt", direction = -1) +
labs(title = "Renta por hogar anual neta media por hogar en Neo-España.") +
theme(plot.title = element_text(face="bold", size=18))+
labs(subtitle = "Año 20XX.") +
labs(fill = "Renta en miles de €:") +
labs(caption = "Datos obtenidos en la web del INE (manipulados para que las estadísticas molen más).") +
theme_void() +
theme(panel.background = element_rect(fill = "azure"),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank())
#- mapa_renta_sin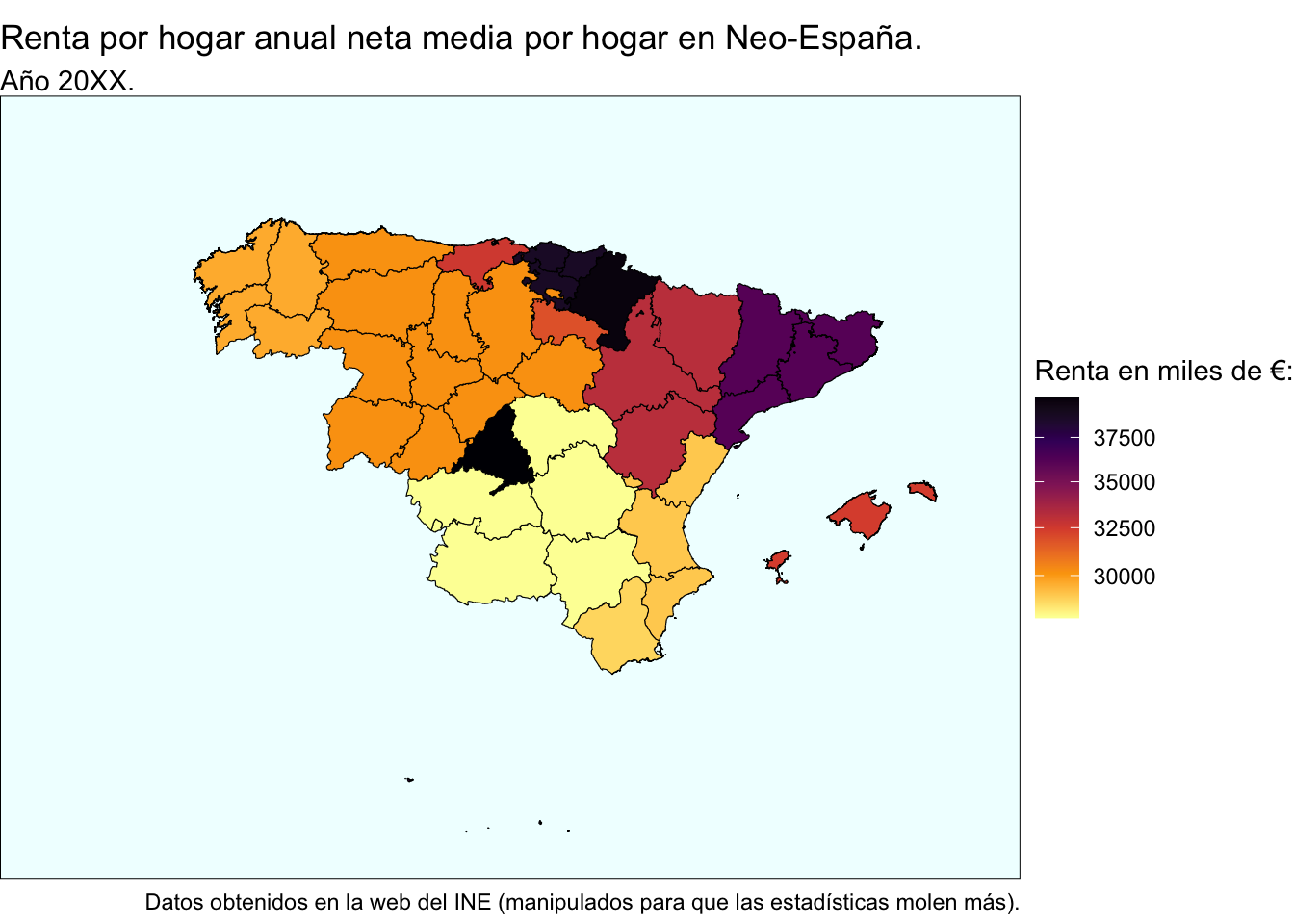
Vemos en la escala de la derecha que el intervalo de renta ha subido considerablemente, lo que nos permitiría escalar en las estadísticas internacionales de bienestar y, aparentemente, converger; al final hay que pensar que son eso, estadísticas, y con tal de cumplir el objetivo de convergencia que hemos propuesto al principio del trabajo, todo vale, ¿o no 🤔🤔?
Conclusiones
Bueno, espero que la lectura le haya resultado amena al lector, al final, el objetivo era poder programar varias cosas y pásarmelo bien haciendo el trabajo (espero poder haber transmitido esto a quien lo haya leído). Por otro lado, la situación en la que nos encontramos actualmente como sociedad es complicada, es complicado saber que hay que hacer o dejar de hacer, mucha gente propone soluciones, muchas de ellas populistas, disparatadas, y sin sentido, el objetivo también ha sido satirizar un poco sobre ese sector de la sociedad que cree tener la verdad absoluta y que el país podría arreglarse en una semana. Por mí parte, estoy contento con el país que tenemos y, a pesar de tener que mejorar en muchos aspectos, me gusta España y quiero que mi futuro se siga desarrollando aquí. Por lo que el único consejo serio del trabajo sería: valoremos lo que tenemos y cuidémoslo.
Información sobre la sesión
Abajo muestro mi entorno de trabajo y paquetes utilizados
current session info
─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.3.1 (2023-06-16)
os macOS Ventura 13.2.1
system x86_64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Europe/Madrid
date 2024-01-23
pandoc 2.19.2 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
abind 1.4-5 2016-07-21 [1] CRAN (R 4.3.0)
assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.3.0)
backports 1.4.1 2021-12-13 [1] CRAN (R 4.3.0)
base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.3.0)
broom 1.0.5 2023-06-09 [1] CRAN (R 4.3.0)
bslib 0.6.1 2023-11-28 [1] CRAN (R 4.3.0)
cachem 1.0.8 2023-05-01 [1] CRAN (R 4.3.0)
cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.3.0)
class 7.3-22 2023-05-03 [1] CRAN (R 4.3.1)
classInt 0.4-10 2023-09-05 [1] CRAN (R 4.3.0)
cli 3.6.2 2023-12-11 [1] CRAN (R 4.3.0)
clipr 0.8.0 2022-02-22 [1] CRAN (R 4.3.0)
codetools 0.2-19 2023-02-01 [1] CRAN (R 4.3.1)
colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)
crayon 1.5.2 2022-09-29 [1] CRAN (R 4.3.0)
crosstalk 1.2.0 2021-11-04 [1] CRAN (R 4.3.0)
crul 1.4.0 2023-05-17 [1] CRAN (R 4.3.0)
curl 5.2.0 2023-12-08 [1] CRAN (R 4.3.0)
data.table 1.14.8 2023-02-17 [1] CRAN (R 4.3.0)
DBI 1.1.3 2022-06-18 [1] CRAN (R 4.3.0)
desc 1.4.2 2022-09-08 [1] CRAN (R 4.3.0)
details 0.3.0 2022-03-27 [1] CRAN (R 4.3.0)
dichromat 2.0-0.1 2022-05-02 [1] CRAN (R 4.3.0)
digest 0.6.34 2024-01-11 [1] CRAN (R 4.3.0)
dplyr * 1.1.3 2023-09-03 [1] CRAN (R 4.3.0)
DT * 0.29 2023-08-29 [1] CRAN (R 4.3.0)
e1071 1.7-13 2023-02-01 [1] CRAN (R 4.3.0)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.3.0)
evaluate 0.23 2023-11-01 [1] CRAN (R 4.3.0)
extrafont 0.19 2023-01-18 [1] CRAN (R 4.3.0)
extrafontdb 1.0 2012-06-11 [1] CRAN (R 4.3.0)
fansi 1.0.6 2023-12-08 [1] CRAN (R 4.3.0)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)
fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)
fontawesome 0.5.2 2023-08-19 [1] CRAN (R 4.3.0)
fontBitstreamVera 0.1.1 2017-02-01 [1] CRAN (R 4.3.0)
fontLiberation 0.1.0 2016-10-15 [1] CRAN (R 4.3.0)
fontquiver 0.2.1 2017-02-01 [1] CRAN (R 4.3.0)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)
gdtools 0.3.4 2023-10-15 [1] CRAN (R 4.3.0)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)
gfonts 0.2.0 2023-01-08 [1] CRAN (R 4.3.0)
gganimate * 1.0.8 2022-09-08 [1] CRAN (R 4.3.0)
ggplot2 * 3.4.4 2023-10-12 [1] CRAN (R 4.3.0)
ggthemes * 4.2.4 2021-01-20 [1] CRAN (R 4.3.0)
gifski 1.12.0-2 2023-08-12 [1] CRAN (R 4.3.0)
glue 1.7.0 2024-01-09 [1] CRAN (R 4.3.0)
gt * 0.9.0 2023-03-31 [1] CRAN (R 4.3.0)
gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)
gtExtras * 0.5.0 2023-09-15 [1] CRAN (R 4.3.0)
highcharter * 0.9.4 2022-01-03 [1] CRAN (R 4.3.0)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)
hrbrthemes * 0.8.0 2020-03-06 [1] CRAN (R 4.3.0)
htmltools 0.5.7 2023-11-03 [1] CRAN (R 4.3.0)
htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)
httpcode 0.3.0 2020-04-10 [1] CRAN (R 4.3.0)
httpuv 1.6.11 2023-05-11 [1] CRAN (R 4.3.0)
httr 1.4.7 2023-08-15 [1] CRAN (R 4.3.0)
igraph 1.5.1 2023-08-10 [1] CRAN (R 4.3.0)
jpeg * 0.1-10 2022-11-29 [1] CRAN (R 4.3.0)
jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.3.0)
jsonlite 1.8.8 2023-12-04 [1] CRAN (R 4.3.0)
KernSmooth 2.23-21 2023-05-03 [1] CRAN (R 4.3.1)
knitr 1.45 2023-10-30 [1] CRAN (R 4.3.0)
labeling 0.4.3 2023-08-29 [1] CRAN (R 4.3.0)
later 1.3.2 2023-12-06 [1] CRAN (R 4.3.0)
lattice 0.21-8 2023-04-05 [1] CRAN (R 4.3.1)
lazyeval 0.2.2 2019-03-15 [1] CRAN (R 4.3.0)
leafem 0.2.3 2023-09-17 [1] CRAN (R 4.3.0)
leaflet 2.2.1 2023-11-13 [1] CRAN (R 4.3.0)
leafsync 0.1.0 2019-03-05 [1] CRAN (R 4.3.0)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.3.0)
lubridate * 1.9.2 2023-02-10 [1] CRAN (R 4.3.0)
lwgeom 0.2-13 2023-05-22 [1] CRAN (R 4.3.0)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)
mime 0.12 2021-09-28 [1] CRAN (R 4.3.0)
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)
paletteer 1.5.0 2022-10-19 [1] CRAN (R 4.3.0)
pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)
pjpv.curso.R.2022 0.0.0.9000 2023-09-20 [1] Github (perezp44/pjpv.curso.R.2022@bd4dd73)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)
plotly * 4.10.2 2023-06-03 [1] CRAN (R 4.3.0)
png 0.1-8 2022-11-29 [1] CRAN (R 4.3.0)
prettyunits 1.2.0 2023-09-24 [1] CRAN (R 4.3.0)
prismatic 1.1.1 2022-08-15 [1] CRAN (R 4.3.0)
progress 1.2.3 2023-12-06 [1] CRAN (R 4.3.0)
promises 1.2.1 2023-08-10 [1] CRAN (R 4.3.0)
proxy 0.4-27 2022-06-09 [1] CRAN (R 4.3.0)
purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)
quantmod 0.4.25 2023-08-22 [1] CRAN (R 4.3.0)
R.methodsS3 1.8.2 2022-06-13 [1] CRAN (R 4.3.0)
R.oo 1.25.0 2022-06-12 [1] CRAN (R 4.3.0)
R.utils 2.12.2 2022-11-11 [1] CRAN (R 4.3.0)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)
raster 3.6-26 2023-10-14 [1] CRAN (R 4.3.0)
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.3.0)
Rcpp 1.0.12 2024-01-09 [1] CRAN (R 4.3.0)
readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)
readxl 1.4.3 2023-07-06 [1] CRAN (R 4.3.0)
rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.3.0)
rio * 1.0.1 2023-09-19 [1] CRAN (R 4.3.0)
rlang 1.1.3 2024-01-10 [1] CRAN (R 4.3.0)
rlist 0.4.6.2 2021-09-03 [1] CRAN (R 4.3.0)
rmarkdown 2.25 2023-09-18 [1] CRAN (R 4.3.0)
rnaturalearth * 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)
rnaturalearthdata * 0.1.0 2017-02-21 [1] CRAN (R 4.3.0)
rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)
rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)
Rttf2pt1 1.3.12 2023-01-22 [1] CRAN (R 4.3.0)
sass 0.4.8 2023-12-06 [1] CRAN (R 4.3.0)
scales 1.3.0 2023-11-28 [1] CRAN (R 4.3.0)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)
sf * 1.0-14 2023-07-11 [1] CRAN (R 4.3.0)
shiny 1.7.5 2023-08-12 [1] CRAN (R 4.3.0)
sp 2.1-2 2023-11-26 [1] CRAN (R 4.3.0)
stars 0.6-4 2023-09-11 [1] CRAN (R 4.3.0)
stringi 1.8.3 2023-12-11 [1] CRAN (R 4.3.0)
stringr * 1.5.1 2023-11-14 [1] CRAN (R 4.3.0)
systemfonts 1.0.5 2023-10-09 [1] CRAN (R 4.3.0)
terra 1.7-55 2023-10-13 [1] CRAN (R 4.3.0)
tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)
tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)
tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)
timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)
tmap * 3.3-4 2023-09-12 [1] CRAN (R 4.3.0)
tmaptools 3.1-1 2021-01-19 [1] CRAN (R 4.3.0)
TTR 0.24.3 2021-12-12 [1] CRAN (R 4.3.0)
tweenr 2.0.2 2022-09-06 [1] CRAN (R 4.3.0)
tweetrmd * 0.0.10 2024-01-22 [1] Github (gadenbuie/tweetrmd@c683b53)
tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)
units 0.8-4 2023-09-13 [1] CRAN (R 4.3.0)
utf8 1.2.4 2023-10-22 [1] CRAN (R 4.3.0)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.3.0)
vembedr * 0.1.5 2021-12-11 [1] CRAN (R 4.3.0)
viridisLite 0.4.2 2023-05-02 [1] CRAN (R 4.3.0)
withr 2.5.2 2023-10-30 [1] CRAN (R 4.3.0)
xfun 0.41 2023-11-01 [1] CRAN (R 4.3.0)
XML 3.99-0.15 2023-11-02 [1] CRAN (R 4.3.0)
xml2 1.3.6 2023-12-04 [1] CRAN (R 4.3.0)
xtable 1.8-4 2019-04-21 [1] CRAN (R 4.3.0)
xts 0.13.1 2023-04-16 [1] CRAN (R 4.3.0)
yaml 2.3.8 2023-12-11 [1] CRAN (R 4.3.0)
zoo 1.8-12 2023-04-13 [1] CRAN (R 4.3.0)
[1] /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/library
──────────────────────────────────────────────────────────────────────────────Notas
Este año se ha alcanzado el récord de gasto en pensiones, 200.000 millones↩︎